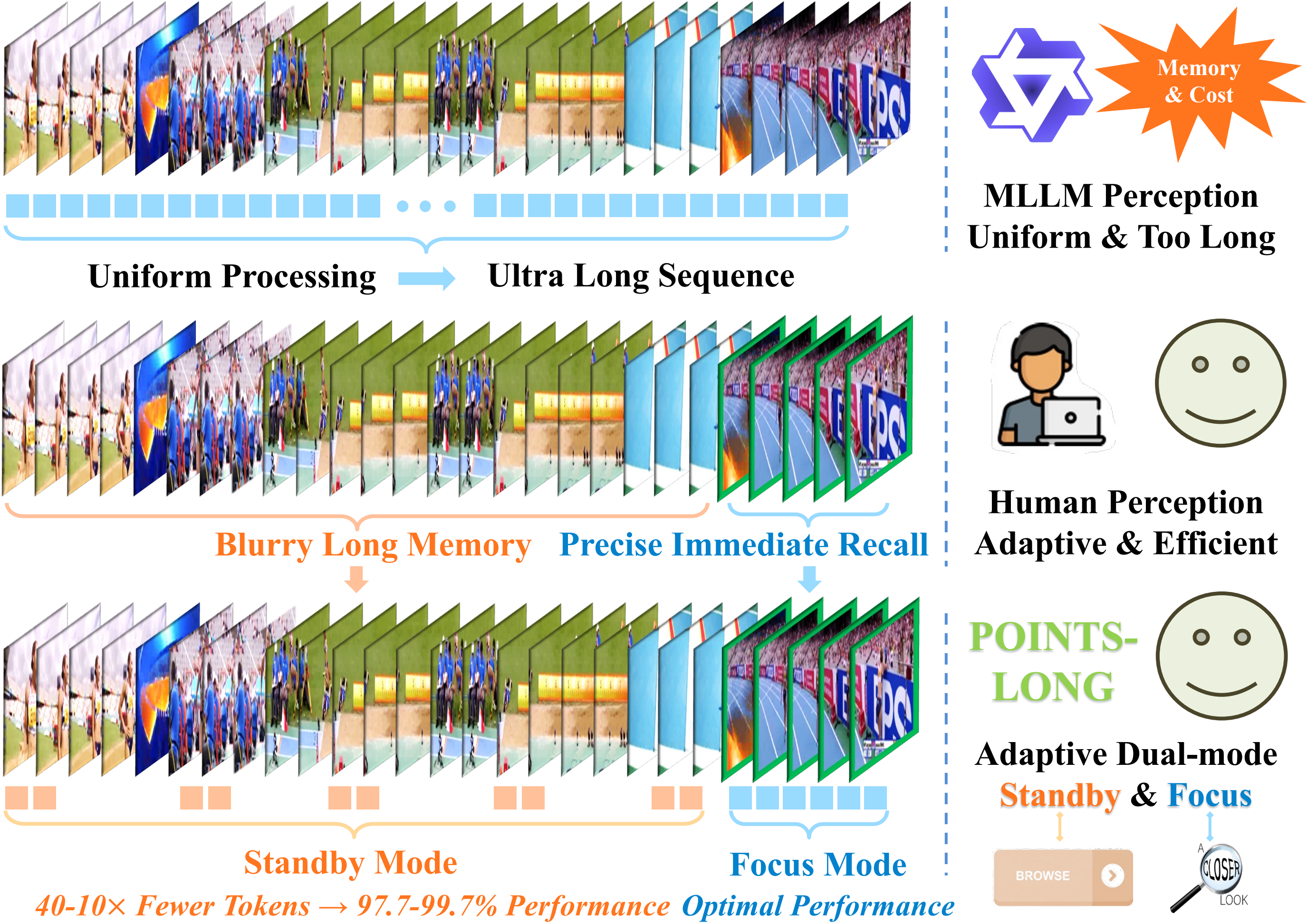
- Native dual-mode perception: a single MLLM that supports Focus (high-fidelity) and Standby (high-compression) visual understanding, enabling an explicit efficiency–accuracy choice at inference.
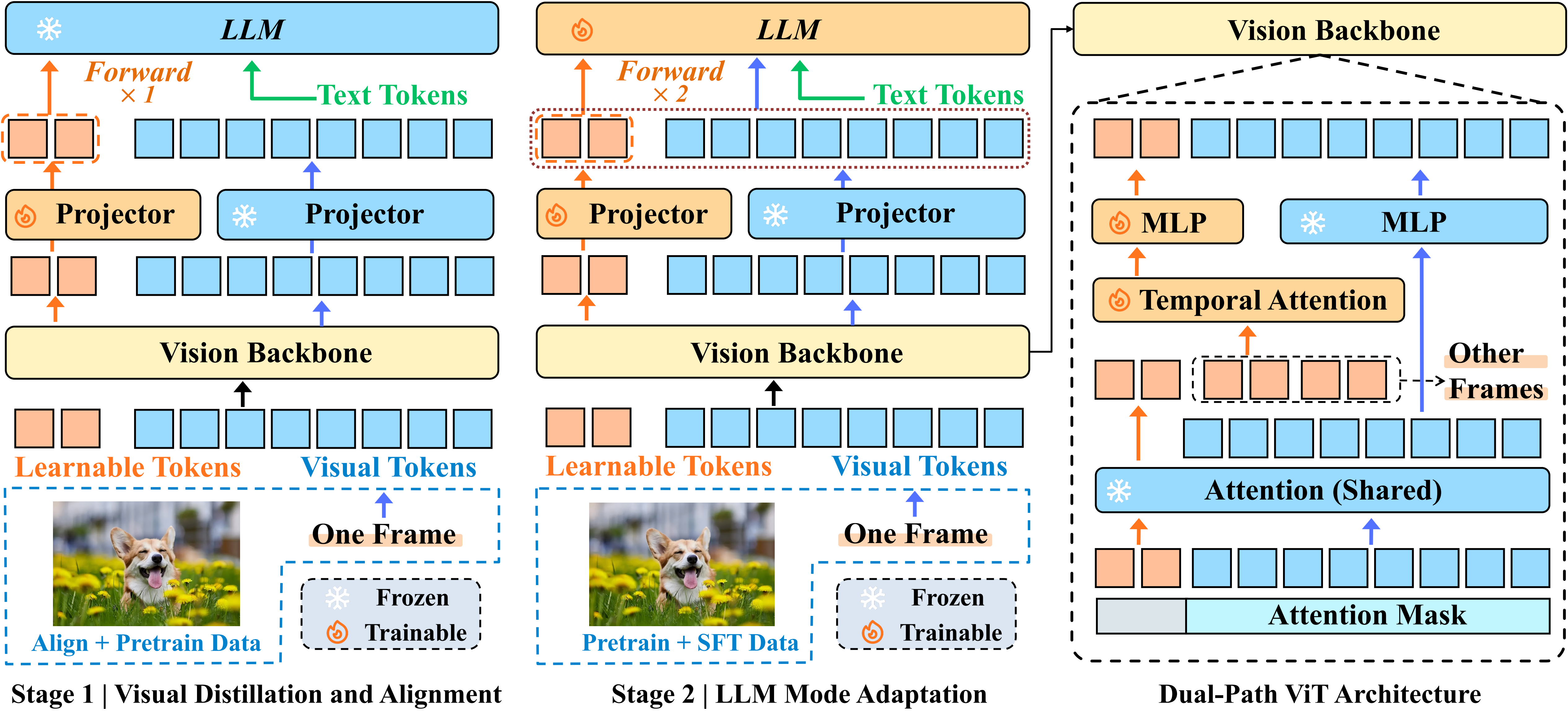
- Two-stage post-training: (i) visual distillation/alignment by training only new modules; (ii) LLM mode adaptation with a 2-forward objective to preserve Focus performance while learning Standby.
- Deployment-friendly design: asymmetric attention masking compatible with modern inference kernels (e.g., FlashAttention) and practical serving frameworks (e.g., SGLang).
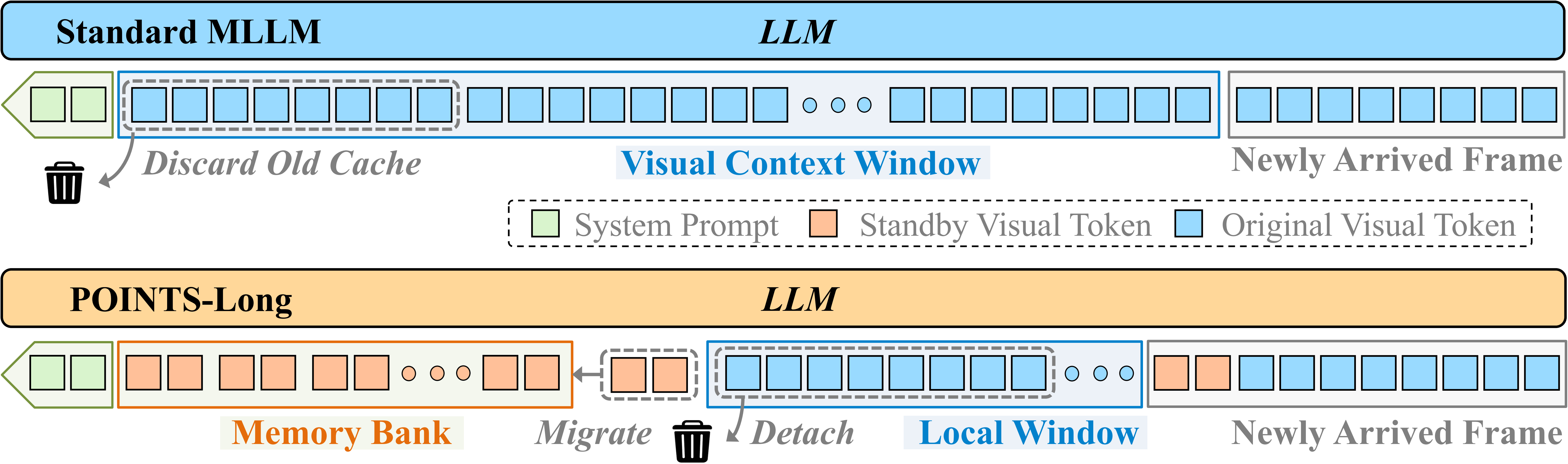
- Streaming-ready memory: detachable KV-cache strategy that retains a high-fidelity local window while migrating compact standby-cache to a long-term memory bank.